



Continuous integration and continuous delivery (CI/CD) is integral to a DevOps approach to software development. But what is CI/CD and why is it key?
For business leaders to effectively strategize with IT teams about their development approaches, this article explores the challenges that CI/CD addresses, tools that support it, and the benefits your organization can expect.
To lay the foundation, let’s consider what DevOps means. The aim of DevOps is to create a software build and deployment process that moves from left to right — from development to operations — with as few handoffs as possible and frequent, fast feedback loops. In practice, this means that application source code moves continuously forward. If a bug is identified or something needs to be fixed, instead of moving backwards, the problem is identified and fixed at the point that it is introduced (continuous testing). Fast feedback loops make this possible. Fast automated testing validates if the code works as it should before moving to the next stage.
To decrease handoffs, small teams work on small functionalities of the software as opposed to an entire feature. They also own the entire process: from request to commit to QA and deployment — from Dev to Ops. (For more background, this article provides a useful introduction to DevOps.)
The idea is to push small pieces of code out quickly. This makes it easier to diagnose, fix, and remediate issues. This workflow is enabled by continuous integration (CI) and extended to production by continuous deployment (CD) — the CI/CD pipeline.
Let’s take a deeper look at CI and CD.
Mastering continuous integration
To achieve a mature DevOps organization, CI must be mastered. In fact, many companies only do CI and leave out the CD part.
CI means integrating code, whether it’s a new feature or an update, that has been developed by a programmer into the codebase. This presents several challenges. All changes must be tracked so that, if an error occurs, you can revert to a previous state and mitigate any service disruption. Conflicts must also be managed when multiple developers are working in parallel. Finally, errors must be catched before they are added to the codebase.
To address these issues, developers can use the following tools:
1. Version control
As code moves through the DevOps process it is constantly being tweaked based on the results of automated testing. These changes are captured in a version control system that keeps track of all changes and other assets in a database, including source code, the software system environment, software development documents, and file changes.
Sidenote: There is some debate about whether sensitive information, such as keys, access tokens, and passwords should be stored in version control. Many believe everything should be stored here while others consider it bad practice and argue that sensitive information should be stored elsewhere. There is no right or wrong answer. Version control will always be a single source of truth that contains all updates and changes to code and reflects the intended state of the system, as well as all prior states. By ensuring all artifacts are stored in version control, developers can reproduce all components of the deployed software system — something that is key to enabling immutable infrastructures (more on that later).
2. Master and developer branches
When multiple developers work on the same project, things can get messy quickly. To reduce the risk of introducing errors or destabilizing the version control master, each developer works on different parts of the system in parallel via branches on their local computers.
However, the code that each developer works on in branches still needs to be integrated into the codebase — a continuously evolving environment. The longer a developer works on code without committing it, the more difficult it becomes. One way around this is to increase frequency or, even better, make it continuous.
The graphic visualizes different branches. The master branch is shown in blue and all other colors are individual developers working on their own branch which are eventually merged into the master branch.
Different branches of the Kublr Docs page: The master branch is shown in blue and all other colors are individual developers working on their own branch which are eventually merged into the master branch. Developers work on their own machine and merge their changes several times a day or by the end of the day.
Continuous integration isn’t without its issues. Even if a developer commits code on a daily basis, conflicts can occur. Other team members may have worked on and committed their own changes, that others didn’t account for. In fact, integration problems often require rework, including manually merging conflicting changes. Mind you, it’s much easier to identify and fix conflicts in a day’s worth of work than a week or month’s worth of coding. Integration problems will occur, but CI significantly reduces them.
3. Deployment pipeline and automated tests
Quality assurance (QA) ensures that errors are caught and code is in a deployable state before code is introduced into the codebase. Before DevOps, QA was typically handled by a separate team once development was complete. These tests were often only performed a few times a year and developers learned about mistakes months after a code change was introduced — making diagnosis very difficult. Automated testing addresses this.
Automated tests are triggered each time code is added to version control. A deployment pipeline tool automatically builds and tests the code to ensure it works as intended and does so once integrated into the codebase. Even with testing, code can still fail once introduced into production environments where the environment and other dependencies can impact code performance. These dependencies are not part of the app, but are required to run it. They include databases, data/object storage, and services for the app to call over an API. This is why dev and test environments must mimic the production environment and code must be tested with all dependencies.
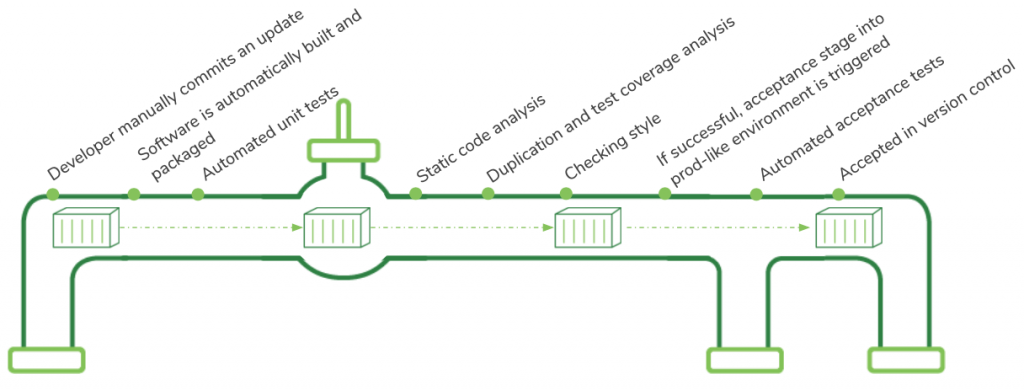
Individual steps when code is committed to version control
To recap, there are three test stages when deploying code, each adding additional complexity:
- Code validation to ensure it works as intended
- Ensuring it continues to do so within the codebase
- Maintaining performance in a production-like environment with all dependencies
When code is committed to version control on a daily basis, it can be tested automatically and any build, test, or integration errors will be flagged immediately so they can be fixed there and then. This way, code is always in a deployable and shippable state — known as a green build. With automation tools, developers can increase test and integration frequency from occasional to continuous and identify problems while there are fewer constraints, ultimately leading to quality software.
Continuous delivery: streamlining code deployment
Deploying code into production, even when continuously integrated, can be a time-intensive, error-prone, manual process. This can limit adoption of CI and lead to significant differences between code to be deployed and code running in production. This is where CD comes into play.
CD extends CI to ensure code runs smoothly in production before it is deployed to users. Canary and blue-green deployments are the most common approach to CD.
With a blue-green deployment, a new component or application version is deployed alongside the current one. The new or “green” version is deployed to production and tested while the “blue” version is still live. If no issues present, then users are switched to the new “green” version of the application.
Canary deployments are similar and start with two versions of the application: the current one and the updated versions. In this scenario, IT will route a small share of user requests to the new version. Meanwhile, code and user behavior are closely monitored. If error rates or user complaints don’t escalate, the share of requests routed to the new version is slowly increased, perhaps from 1% to 10%, 50% to 100%. Once all the new requests are routed to the new version the old one is deleted.
CI/CD calls for a novel approach to IT infrastructure and architecture
With CI/CD explained, let’s take a look at environments and infrastructure since CI/CD calls for a novel approach.
On-demand production-like environment creation
Tools like automated testing enable developers to perform QA themselves. To do this they depend on production-like environments during development and testing. In the past, developers would have to ask the Ops team to manually set these up — a process that could take weeks or months. These manually deployed environments were also often misconfigured or so different from production that even when code was vigorously tested before deployment, problems could still occur in production.
Therefore, a key part of CI/CD is providing developers with on-demand production-like environments where they can run their own workstations. This is important because developers can only mimic how code will behave in production, if they test and deploy it under the same conditions.
Immutable infrastructure and the cattle vs. pets analogy
When we talked about version control, we discussed the need to codify environments with all application artifacts present. This is important because when environment specifics are defined and codified in version control it becomes much easier to replicate environments when capacity is increased (known as horizontal scaling) and can be done at the touch of a button or automated through Kubernetes.
The elasticity of cloud computing has made scaling a critical feature allowing companies to increase compute capacity during peak hours. Netflix, for instance, ensures buffer- free content streaming during busy hours by replicating its streaming components — codified in version control — to match demand. Once streaming capacity returns to normal these “replicas” are destroyed.
To enable this, whenever an infrastructure or application update is deployed it must be automatically replicated elsewhere and added to version control. This ensures that whenever a new environment is created it will match the environments throughout the software build pipeline. So, if Netflix updated its streaming services but omitted capturing that change in version control, it would replicate the faulty or outdated components during peak demand. This could lead to issues or even service disruption.
It’s bad practice to manually alter environments that have been codified in version control which could lead to errors. Instead, changes are added to version control then the environment and code are recreated from scratch. This is known as immutable infrastructure and it’s where the cattle versus pets analogy comes from. Before DevOps, infrastructure was treated like pets — if there is an issue, you’d do anything to ensure it survives. Today, infrastructure is treated like cattle. If there’s an issue or it’s not working properly, you kill it and create a new environment. It sounds like a callous analogy but it is very important and significantly reduces the risk of issues sneaking into the infrastructure.
Why you should decouple application deployment from release dates
In traditional waterfall application development, software releases are driven by “go live” or launch dates — often set by other departments, such as marketing. In this model, new features are deployed into production the day before the release date. It’s a risky business, especially if an entire feature is released at once. This is why tying deployment to the release sets IT up for failure.
A better approach is to decouple application deployment from release. In fact, the two terms are often used interchangeably but they are different. Deployment means installing a software version to an environment, including production. It needn’t involve a “release” — meaning a new feature is made available to users.
This is why CI/CD is important. Frequent production deployments throughout the feature development process reduces risk and is driven by IT. Whereas decisions about exposing new functionalities to users is a business, not an IT decision. If deployment times are long, this will dictate when new features can be released. But imagine if IT could deploy on-demand and expose new functionality to customers and users — this would be a decision driven by the business.
Conclusion
To catch errors as they occur and minimize rework, CI calls for application code to be integrated into the codebase in a continuous way. Continuous delivery extends CI to validate that code is in a deployable state. If it is, it automatically releases it into production.
Achieving this CI/CD pipeline requires a mature DevOps organization — one that has mastered CI before attempting CD.
Implemented well, CI/CD can increase IT productivity and continuously improve your system or application while minimizing risk in deployment. It also enables greater innovation as new application features and updates are deployed quicker, bringing enhanced and more frequent value to customers. This improved productivity also drives greater employee satisfaction.
The competitive advantages of CI/CD are clear. Those who don’t embrace these and other DevOps methodologies will face digital Darwinism.
As usual, a big thanks to Oleg Chunikhin who, with each article, teaches me a little more about cloud native.