



When providing IT services, customer-centric approaches are critical and increase client loyalty — organizations must get it right to remain competitive.
However, during the development of complex pieces of software, application bugs are inevitable. Even if your software is flawless and passes all “correctness” tests, it still depends on the underlying environment, networks, external services, user interactions, and many other factors which may cause it to fail.
While bugs are part of any software development process, we must identify and resolve them quickly before they produce incorrect or unexpected results that impact the customer experience.
Ideally, bugs should be caught before software is pushed to production and causes customer issues. The simplest technique is to collect logging events — erroneous and successful ones alike — and, whenever a feature or update is released, you must analyze them.
The traditional way to do this is using an Information Technology Infrastructure Library (ITIL) – a reactive support approach – but there is a better way.
ITIL vs. Intelligence-Driven Support System
Traditional tech support systems such as ITIL are built on the principle when a customer encounters an issue they create a support ticket which is then added to the problem resolution queue.
To fix the issue, the service operation lifecycle must go through the following stages: 1) fulfillment of user requests, 2) resolution of service failures, 3) problem fixing, and 4) routine operational tasks. The service desk tries to resolve issues within a set SLA and according to developed procedures, which can be a painfully long process for the customer.
In addition to fixing issues, tech support also handles customer support requests or feedback related to changing business flows, even a lack of training — it’s a lot to juggle at once.
With all the telemetry that software produces today, why wait to administer support until the customer reaches out? The data is there. We should be able to identify and fix issues before they impact the customer? Fortunately, there is a way to do just that.
By digitally transforming your issue resolution system, you’ll increase software quality while reducing business risks and improve customer satisfaction. There are numerous technologies that will help you achieve that. In this article, I’ll share what we encountered at a customer site and how our team tackled it.
Reactive support
Our client ran their application on two on-premise load balanced nodes (servers). Log files are written by a nlog library with detailed information about events on each node. These log files are categorized into API tracking events and authentication services, and then again by event date.

Folder with logs on each node (server)
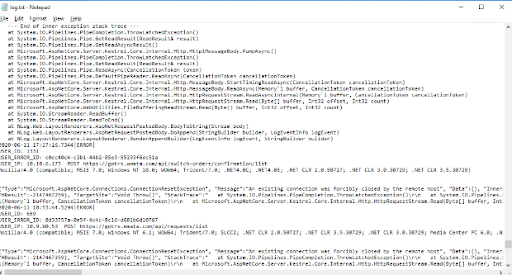
Api log file

Authentication log file
After the deployment to production we began receiving emails from users about issues and questions they had. For each request we tried to reproduce steps the users had taken and find information from plain log files on the production servers. What we found was an abundance of information that was not essential to the specific issue. The process also took up a great deal of time and delayed our time to respond to the users. Also, not all development team members had access to the production system. This resulted in frustration for the development team and the users.
Furthermore, it wasn’t possible to list and view log files page by page or switch between different types and dates. It was clear we needed a tool for log collection, view, filtering and discovery.
The ELK Stack: Your Toolkit
To solve that issue, I put my DevOps hat on. I started to look into an open-source tool in particular, the ELK Stack
The ELK Stack is one of the most popular open source tools among organizations that need to sift through large sets of data and make sense of their system logs. ELK is composed of Elasticsearch, Logstash, Kibana, and Beats. These tools allow you to reliably and securely take data from any source, in any format, then search, analyze, and visualize it in real time.
A great feature of these products from the deployment perspective is that they can be installed in many ways and on many platforms, including Kubernetes. It took approximately two days for me to install and set up ELK Stack on my PC (in Kubernetes). Check out this resource for ELK Stack installation tips.
Anticipate customer needs
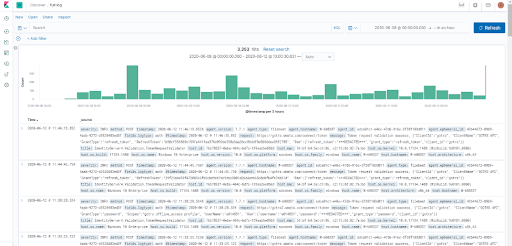
After setting up the ELK Stack, we acquired a powerful mechanism to solve upcoming issues. With it we can find and quickly investigate the incidents that customers claimed. We can also see similar issues that other users have experienced and, should a bug arise, offer a workaround to all of them on the spot. We can also monitor and analyze events as they happen and visualize the health of the system from a business perspective.
As ELK updates logs in almost real time, we can be proactive in error detection and contact the customer with a potential solution before they contact technical support.
Real life examples
To bring this idea to life, I’ll share a few real life examples and how our team addressed them. You can use a similar approach to identify issues and empower users to help themselves by providing them with the right tools.
1. A new version of an application is often released with new features and changed business flows.
In response to a change in requirements, a new acknowledgment option was added to our application as a checkbox on one form. This option is mandatory when editing an entity in a specific state. Previously, users weren’t required to acknowledge this business process. However, after the application was released, we found that users continue to ignore this option.
Seeking to rectify the issue we found the messages with text “Failed to perform.”, and http request parameters without option “isAcknowledged”, by filtering API logs on a by error log level.
We set up automatic alerts with required actions for users when they repeated the incorrect action. These alerts were delivered via Microsoft Teams, a messaging tool, which was preinstalled on all customer devices. Instead of traditional emails, users receive push notifications to their mobile devices seeing messages immediately.
Without this approach, users would have to send an email or call the technical support team. Then a ticket would be created and escalated to the necessary level of support. The process, including waiting for an agent to respond, takes time. In this old approach, users are supported by the principle: one support request — one answer.
Another solution that could have been implemented in this case, is to develop a release with a warning message that provides clear instructions to users. But this solution also takes much time — requirements would need to be created, implementation and regression tests carried out, and a full release cycle performed.
With our log analysis and alerting system, we transformed the support process and served all users who experienced this type of issue in near real time.
| Before | After |
|---|---|
Before
|
After
|
2. Access to documents in the application is defined by user role.
There are two types of roles allowed to edit “Service Hours Adjustment” document types in the system: supervisor and user. According to requirements, a user should be able to create and edit “Service Hours Adjustment” documents.
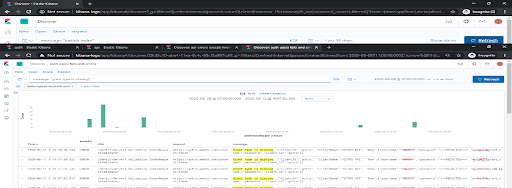
However, analysis of logs by error log level showed us that an error appeared with a “not authorized” message in response.
Requests, users, and parameters in the log details helped us identify what the user was trying to do. Then we repeated this action in the staging environment where a result was reproduced. We found that the user didn’t have access to edit a document. In this case the user with id 1087 tried editing the document with 11213 id on June 12 , 12:57:15. After this try, api returned “Forbidden” response status.
Program code analysis showed that access was restricted to only one role: only users with higher privileges had editing rights.
To suggest workarounds, we set up and automatically sent notifications through Microsoft Teams to both users letting them know that the supervisor could edit the document on behalf of the user or the supervisor could temporarily promote the user to supervisor privileges. Then a hotfix was deployed, and users were informed the bug was fixed.
Without log analysis we may have missed this defect since users don’t often report bugs. If they do, support will escalate through all levels and be resolved much later than we did. In our case we discovered the bug and suggested a workaround before the user asked support.
3. The system has an authentication form with login and password. Several users claimed an issue when they were unable to log in. Analysis of the authentication logs helped to detect the issue.
Users with certain special characters in their password were experiencing problems logging into the system. We confirmed the bug by reproducing it in the staging environment. As a workaround we suggested users to temporarily change their passwords to one without special characters. Then we started monitoring new events with this error type and sent automated notifications through Microsoft Teams to users recommending updating their passwords. A hotfix was created later to cover this bug.
4. While the application is generally used on the intranet, however customers can connect to their workplace through a variety of options, such as VPN, RDP through web-VPN, and run the application directly inside a web-VPN solution (web-proxy)
Access through a web-proxy wasn’t part of the initial requirements and thus not yet supported. We identified this error in the logs with specific IP addresses and ensured users attempting to log in via a web-proxy were prompted to login through VPN or RDP connections until it was fixed with the next release.
Conclusion
As you can see, shipping and collection logs, monitoring, grouping, systematization, discovery and analysis can help businesses prevent delays in support workflows, mitigate system degradation and outage, and save significant time on issue escalation and investigation.
With the help of modern tools such as ELK Stack, Microsoft Teams, integration alerts and notifications, businesses can transform their technical support from a reactive operation to a streamlined, efficient, and proactive operation.
By leveraging new technologies across the software support lifecycle companies can catalyze their digital transformation initiatives — across multiple systems — in a single module, creating a flexible architecture.
This transformation to a proactive customer support model can quickly generate value thanks to modular, loosely coupled components.