



Most organizations have legacy systems that are deployed and used in production. Hopefully, most of them are well maintained and don’t require much time to support. Unfortunately, there are typically one or two applications that require extraordinary effort each time a new feature, however small, is developed. In such systems, even critical bugs can linger for a long time due to the workarounds built into the system.
These legacy systems are often too valuable to get rid of yet too expensive to maintain. The system may be a project that was developed a long time ago using an obsolete technology stack. It may also be a code base your organization inherited after a business acquisition. The backstory of each legacy system differs, but they all pose the same question: how can developers work effectively with legacy systems and legacy code?
Refactor or Rewrite?
There are three major ways to deal with a legacy system:
- Leave it as is
- Rewrite it
- Refactor it
If the legacy system works well enough and your organization doesn’t require a lot of new features or bug fixes, then the simplest option is to just leave that system as is, without refactoring or rewriting it. Sometimes, the simplest way is also the right way.
But if the legacy system requires active development in a form of new features or constant bug fixes, you must take action. Trying to evolve such a system without putting effort into changing its underlying structure will quickly become prohibitively expensive.
So, which approach to choose? Rewrite this system from scratch or gradually refactor it?
The answer depends on the project specifics, but in general, you should choose the full rewrite in one of the following two situations:
1. The project’s code base is small – If the legacy system isn’t too large, then its full rewrite becomes a viable option.
But beware: if the rewrite can’t be realistically completed within several months, the risks of the full rewrite become too significant.
What are those risks?
For one, the longer it takes to complete a project, the greater the risk of delaying it, which in turn increases the risk of not delivering it at all.
Secondly, if the legacy system is still getting updates, the new system will need to continuously catch up with it functionality-wise. The organization may end up supporting two versions of the same system for a long time.
2. The project’s technology stack is not compatible with the stack your organization uses currently – If the older system is written in COBOL or other lesser-used programming language, then rewriting it from scratch becomes the only option, because you may simply not find developers willing to refactor that system using the existing technology stack.
In all other cases, consider refactoring over a rewrite. Refactoring will allow you to improve the quality of the code base while still delivering business value in the form of new features.
The Refactoring Strategy
The refactoring should follow the following strategy (even if you must do a full rewrite due to incompatible technology stacks, you should still take the same approach):
1. Identify a small piece of functionality that is loosely connected to the rest of the system. The smaller that piece, the better.
2. Declare this functionality a separate bounded context. A bounded context is a part of the project that is logically separated from the rest of that project. For example, your legacy system may consist of three main areas: product catalog management, sales, customer support. All these areas tackle different aspects of the business; they are logically separated from each other. All three can be represented as separate bounded contexts.
The goal of defining a new bounded context is to put clear boundaries between the new and the old code. The new code can now adhere to best practices of coding, with clean and simple architecture, free from the influence of the old code.
3. Create an anticorruption layer around the new bounded context. In order to prevent the old code practices from influencing the new code, you must maintain a clear separation between the two. This separation takes the form of an anti-corruption layer – a logical layer in your code base. The bounded context will talk to that layer on its own terms, and the layer will translate these communications into legacy terms and vice versa.
Eventually, the bounded context will grow until it absorbs all the legacy code, at which point the anti corruption layer can be removed.
This approach combines the benefits of a full rewrite and a gradual refactoring without having to deal with their drawbacks.
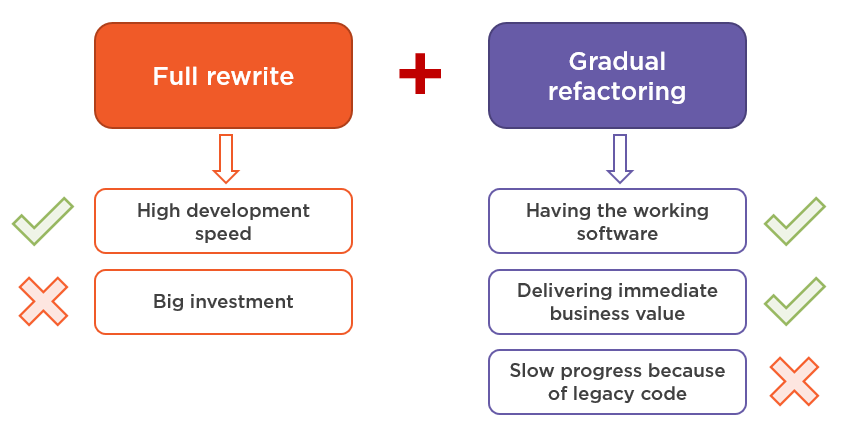
The benefit of a full rewrite is that because the code is new, you have a high development speed as the existing legacy system doesn’t slow you down. It also helps with the team morale. The problem with the full rewrite is that it’s a big upfront investment.
On the other hand, with gradual refactoring – meaning, refactoring only one piece of code at a time, without declaring a bounded context – you have the working software at each step of the development process. Moving gradually allows for improving a single piece of code at a time while still delivering the immediate business value in the form of new functionality. However, the major drawback is that the team must frequently deal with the legacy code base. Depending on the quality of that code base, it can slow down the refactoring significantly.
With the new bounded context, you can build a new and clean code base, but at the same time, it doesn’t take you too much time to do so because the size of that code base is very narrow. As a result, your team can have the working software at each step of the development process.
Anticorruption Layer
There are several ways to implement the anticorruption layer. When you start out with the bubble context and build up a new domain model, the anticorruption layer may be just a repository – a class that retrieves data from the legacy database and saves it back. Such a repository will know which parts of the legacy database to look at to gather information required to materialize new domain classes. It will also know how to persist them back to the legacy database without violating any implicit and explicit data integrity rules.
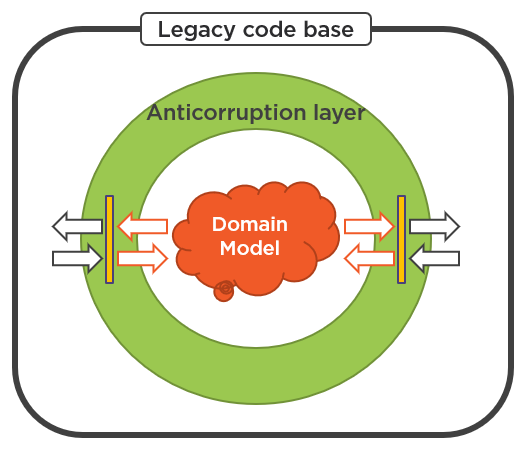
But as you continue to develop new functionality in the bubble context, you will eventually outgrow the simple repository. There are several issues with this type of the anticorruption layer:
- You are limited to the data stored in the legacy application. Without its own storage, the bubble context will be limited to the data from the legacy database.
- Any modifications of the database will contribute to the legacy part of your codebase. If you want to expand the database (say, introduce additional columns or tables), you must do that in the existing legacy database and thus contribute to the already high technical debt of the legacy system.
The solution is to promote your bubble context into an autonomous bubble and your anti corruption layer – into a synchronizing anti corruption layer.
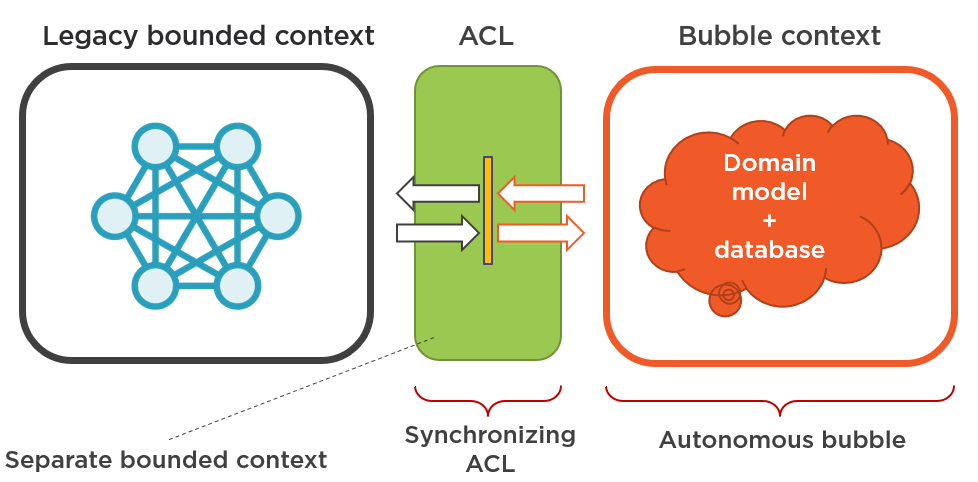
An autonomous bubble differs from a regular bubble context in that it has its own database. The synchronizing anticorruption layer also becomes significantly larger in scope, and so should be treated as a separate bounded context.
Unlike the regular anticorruption layer, the synchronizing anticorruption layer is an independent piece of software. Its purpose is to keep the new and the old database in sync with each other.
There are several benefits to this approach:
- The bubble context can now store its data in a native format, without any connection to the legacy database. This allows you to design its structure as if there were no legacy database whatsoever, using all the best practices.
- It’s much easier to test such a bubble context as you don’t need to set up the legacy database in order to perform integration testing. All this complexity has moved to the synchronizing anticorruption layer.
There are also some drawbacks to consider:
- The anticorruption layer becomes more complex. Because of that, you should introduce a synchronizing anti corruption layer only when the complexity increase is justified – when a regular repository is not enough anymore.
- The synchronization between the legacy database and the bubble context becomes asynchronous, i.e. not immediate. It requires clear separation of data ownership between the old and the new applications. Each piece of data should be modified only by one of the applications. The other application should merely copy these modifications. Such data ownership is required in order to avoid race conditions and issues with synchronization.
Overall, the autonomous bubble context and its synchronizing anticorruption layer becomes a piece of software in its own right. As you continue with its development, you will gain more territory by refactoring the legacy part of the application. This approach is also called the Strangler pattern.
It’s also important to maintain a good unit test suite in order to prevent any bugs that might occur during the refactoring. A good source on the topic of unit testing is my book: Unit Testing Principles, Practices, and Patterns.