



As a technology company focused on complex project integrations that unify legacy systems as well as modular solutions that ensure lasting scalability, we work on a multitude of projects that involve custom software development; packaged, open source, and SaaS software integration; infrastructure setup; and production operations and maintenance.
From a technology standpoint, our approach is always agnostic. We work with Java and .Net backends, web and mobile (all platforms), Amazon and Azure cloud services and infrastructure, and even on-premises deployments.
Containerization has been a de-facto standard for us for quite some time as a way to manage complex systems and processes, but with so much complexity and so many technologies at play, we are always seeking new ways to improve the efficiency of our work, reuse what we do, and focus our team on the unique business requirements of each project.
One way to do this is through the application of a flexible and reliable platform for managing complex multi-component clustered containerization software – building reusable components for various DevOps needs, and supporting production operation and reuse.
One way to improve the efficiency of our work
is through the application of a flexible and
reliable platform for managing complex
multi-component clustered containerization
software.
Among the requirements for the platform we identified the following:
- Avoiding vendor lock as much as feasible. The platform needed to be portable (able to run on different clouds and on-premises), it had to rely on open standards and protocols. It also needed to serve as the basis for a large number of projects, services, and organizations.
- Suitability for different business environments. This necessitatesopen source technologies with permissible license, the availability of commercial support, as well as free options.
- Scalability. Support for configurations ranging from extra-small (e.g. one physical or virtual node), to large (dozens of nodes), to extra-large (hundreds and thousands of nodes).
- Reliability. We needed support for various self-recovery and fail-over scenarios for different environments and scaling.
- Flexibility and feature-richness. We expected a number of features and abstractions necessary for development, efficient DevOps, and production operations automation.
- Ease-of-deployment. Easy to deploy and setup in different environments, preferably out-of-the-box. It also needed to be lightweight, production-ready, and battle-tested.
The Path to the Solution
Several frameworks exist, that could serve as a basic for the solution, but the following three made the list of realistic contenders:
- Docker Swarm
- Kubernetes
- Hashicorp stack of tools - nomad, consul etc.
- (with an honorable mention to Apache Mezos)
After some research and prototyping we identified Kubernetes as the main candidate for our standard DevOps and cluster orchestration platform – for a number of reasons.
Kubernetes – The Pros
It’s not the goal of this post to describe in detail how we compared the tools, but I'd like to give a brief summary of where Kubernetes really shines:
- The idea of pods, sets of co-located containers, is very powerful; it solves the same problem as Docker Compose, but in a more elegant fashion. Pod, rather than container, is actually a workload unit in Kubernetes.
- Flat overlay network address space, where every pod gets a unique IP address, and containers within a pod communicate via localhost.
- "Service" abstraction provides simple service discovery via a stable overlay network IP address for an L3 balanced set of pods.
- DNS further enhances service discovery. Pods are able to find services by their names.
- Namespaces. These enable objects to be separated into groups and provide a means for multi-tenancy within a single cluster.
- A rich set of pod controllers available out-of-the-box: deployments, replica sets, and replication controllers for symmetrical clusters; pet sets for clusters where component identity is important; daemon sets for auxiliary components, such as log shippers and backup processes; ingresses for reverse proxy and L7 load balancing; and many more.
- Notion of add-ons, providing “cross-cutting concern” features.
- Rich persistent storage management capabilities.
- Good integration with most IaaS cloud providers.
All in all, in my opinion, Kubernetes strikes the right balance between "too much abstraction, need to write a lot of boilerplate code" and "too little abstraction, the system is not flexible".
Kubernetes strikes the right balance between
"too much abstraction, need to write a lot of
boilerplate code" and "too little
abstraction, the system is not flexible".
Kubernetes – The Cons
Unfortunately, even the sun has dark spots - Kubernetes is notoriously difficult to setup for use in production.
Kubernetes is notoriously difficult to
setup for use in production.
Our requirements for the platform setup process were mainly derived from general platform requirements; we wanted to do the following:
- Setup a "vanilla" Kubernetes cluster, not a customized product based on Kubernetes.
- Be able to customize the cluster configuration and setup process easily.
- Simplify the setup process and reduce requirements to the administrator's environment as much as possible.
- Make the deployment process portable and re-usable, so that we can maintain it on multiple platforms - at least Azure, AWS and bare metal.
- Rely on cloud provider specific tools for IaaS resource management - Cloud Formation for AWS, resource manager for Azure.
- Ensure that the resulting deployment is production ready, reliable, self-healing, scalable, etc. (i.e. satisfies all the requirements to the platform described above).
There are many ways to setup a Kubernetes cluster, some of them are even part of the official documentation and distribution, but looking into each of them we saw different issues preventing them from becoming a standard for EastBanc Technologies’ projects. As a result, we designed and built a Kubernetes cluster setup and configuration process that would work for us.
Kubernetes Deployment Re-Imagined
For our Kubernetes deployment procedure we decided to rely on cloud provider tools for IaaS resource management, namely Cloud Formation for AWS and Resource Manager for Azure.
Thus to create a cluster, you don’t need to
setup anything on your machine, just use the
Cloud Formation template and AWS console
to create a new stack.
To create a cluster, you don’t need to setup anything on your machine, just use the Cloud Formation template and AWS console to create a new stack. The Kubernetes cluster Cloud Formation template we implemented creates several resources, as described in the following diagram:
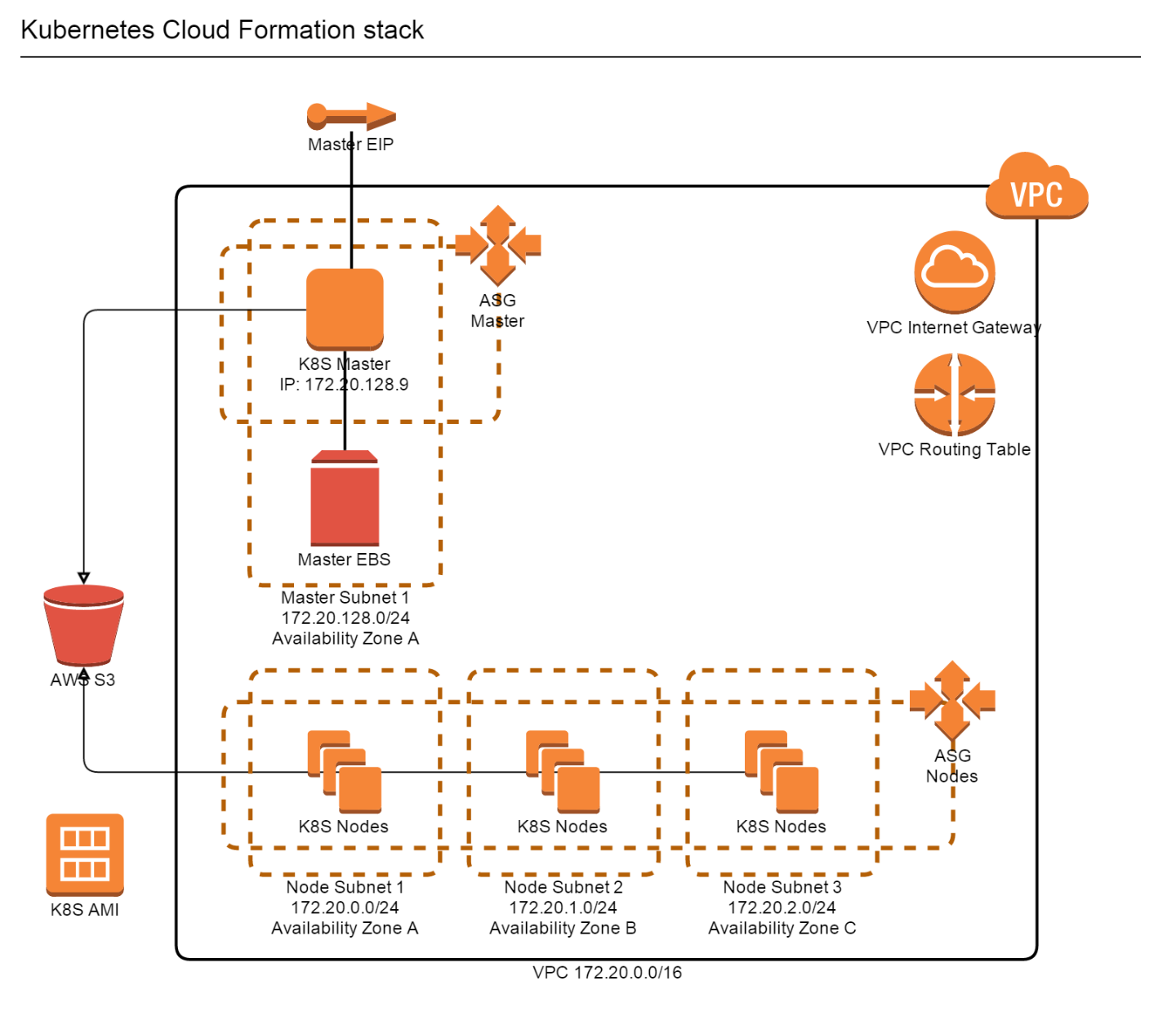
Let’s take a look at these resources in a little more depth:
- Master EIP provides a stable public end point IP address for the Kubernetes master node.
- On startup, the Kubernetes master initialization script also assigns a standard private IP address (127.20.128.9) to ensure that the master node also has a stable private endpoint for node Kubelets.
- Master EBS is attached to the master node on startup and is used to store the cluster data.
- Kubernetes master is started in an Auto Scaling Group to ensure that AWS recovers it in case of failure. Currently master Auto Scaling Group has minimum, desired, and maximum number of instances set to 1.
- Nodes are running in an auto-scaling group in multiple availability zones.
- S3 bucket is used to share certificates tokens for nodes and clients to connect to master.
- Master will generate certificates and tokens on the first startup and upload them to the bucket.
- Master and nodes are assigned IAM roles with access rights to required AWS resources.
- Master and node instances are created from an AMI with all software components required for Kubernetes pre-installed.
To configure Kubernetes software components running on the master and the nodes, we used portable multi-node cluster configuration approach described in Kubernetes documentation.
The following diagram shows the resulting software configuration:
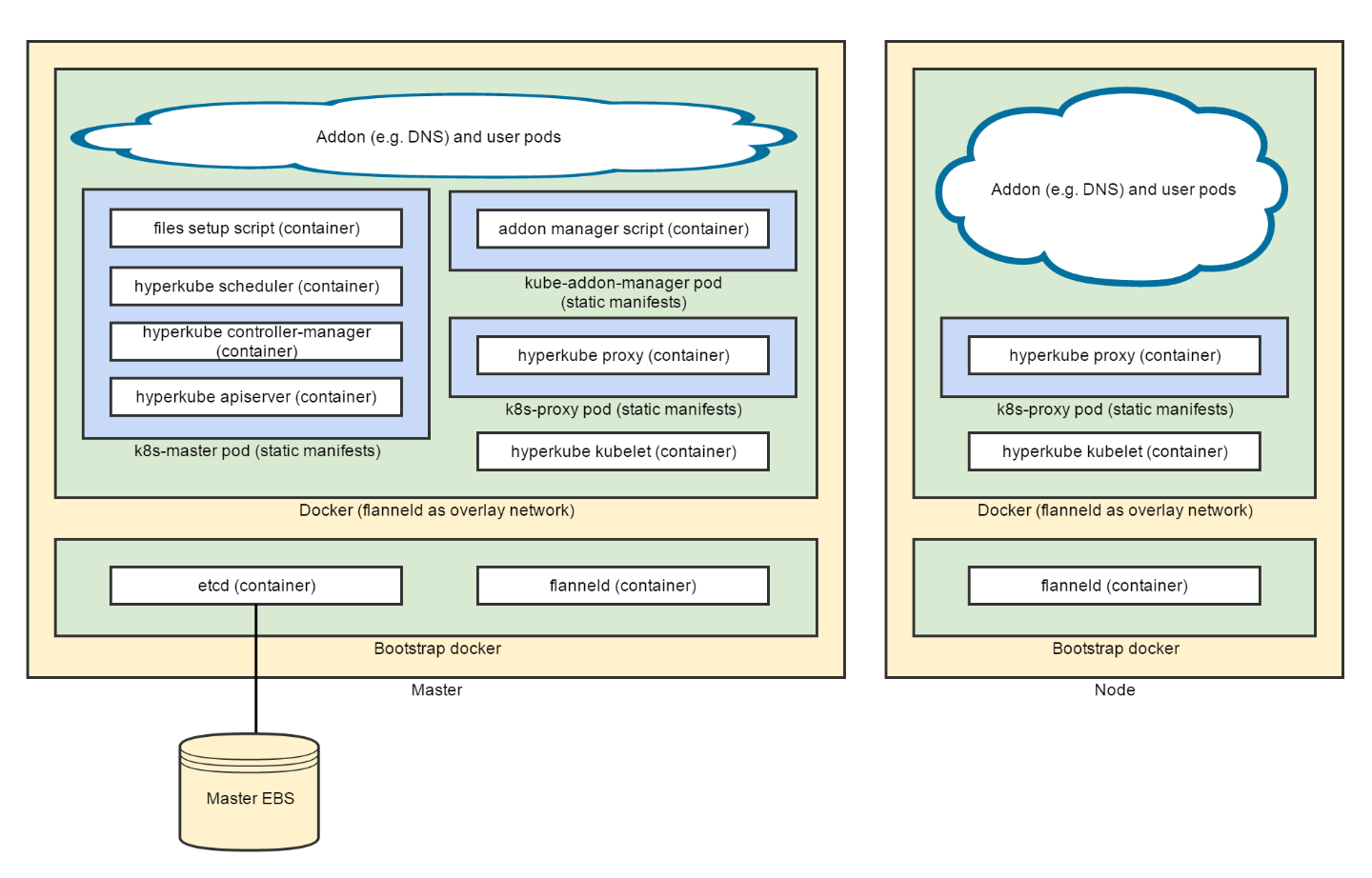
The cluster initialization steps are split into three categories:
- Packer script preparing AMI for the cluster.
- Cloud Formation template creating or updating AWS resources for the cluster.
- A bootstrap script running as the last step of the master or node instance boot process.
AMI Preparation
We built a customized AMI for the cluster based on the official Kubernetes AMI k8s-debian-jessie, which is in turn just a standard Debian Jessie image with some additional packages installed.
AMI preparation is implemented via packer script. The following steps are then performed:
- Update installed packages.
- Create docker-bootstrap service in addition to docker service, that is already configured in the base image.
- Update docker systemd service configuration so that the flanneld overlay network can be configured on the service startup.
- Pull etcd, flanneld, and Kubernetes hyperkube Docker images to ensure fast and reliable node startup.
- Create /etc/kubernetes/bootstrap script and add its execution into /etc/rc.localscript so that it runs as the last step of OS boot sequence.
- Prepare static pod manifest files and Kubernetes configuration files in/etc/kubernetes.
- Prepare other auxiliary tools used during instance bootstrap (such assafe_format_and_mount.sh script).
- Ensure that /srv/kubernetes directory is mounted as tmpfs (to provide for safe storage of secret keys and certificates.
- Cleanup temporary and log files.
Cloud Formation Template
The Cloud Formation template creates and initializes AWS resources as shown in the first diagram above. As a part of this configuration, it creates launch configuration objects for Kubernetes master and node instances, and associates them with master and node auto scaling groups.
Both master and node launch configurations include AWS User Data scripts, that create/etc/kubernetes/stack-config.sh file in which several environment variables are set.
These environment variables are used by /etc/kubernetes/bootstrap script to acquire context information about the environment it is running in.
In particular, Master EIP, instance role (whether this is a Kubernetes master or node instance), and S3 bucket name are passed this way.
Instance Bootstrap Script
Instance bootstrap script runs as the last step in the instance boot sequence. The script works slightly differently on the master and the nodes. The following steps are performed as part of this process:
On all nodes:
- Load context and environment information from the /etc/kubernetes/stack-config.sh file.
- Disable the instance IP source destination check using AWS CLI to ensure that IP routing works correctly for the Kubernetes overlay network.
On master only:
- Attach Master EBS and ensure that it is formatted and mounted.
- Attach Master EIP.
- Associate the stable private IP.
- Check if tokens and certificates files are present in the S3 bucket.
- If S3 bucket does not contain required files, generate them and upload to the bucket.
- If S3 bucket contains the required files, download them to /srv/kubernetesdirectory.
- Ensure that docker-bootstrap service is started.
- Run etcd as a container in docker-bootstrap.
- Set flanneld configuration keys in etcd.
On nodes only:
- Wait until S3 bucket contains required files.
- Download the files to /srv/kubernetes directory.
On all nodes:
- Ensure that docker-bootstrap service is started.
- Run flanneld as a container in docker-bootstrap.
- Configure docker to use flanneld as an overlay network and restart.
- Configure kubelet and kube-proxy.
- Start kubelet container.
After kubelet is started on the master, it takes care of starting other Kubernetes components (such as apiserver, scheduler, controller-manager, etc.) in pods as defined in static manifest files, and then keeps them running. Kubelet started on nodes only starts kube-proxy in a pod and then connects to master for further instructions.
Working with the New Cluster
As soon as master is started and fully initialized, the administrator can download the Kubernetes client configuration file from the S3 bucket. The files in the bucket are only accessible by the master EC2 instance role, the node EC2 instances role, and AWS account administrator.
The cluster REST API is available via HTTPS on a standard port on the master EIP.
Security, Reliability, and Scalability as Standard
As a result of our efforts, we now have a simple way to setup a reliable production ready Kubernetes cluster on AWS.
We now have a simple way to setup a reliable
production ready Kubernetes cluster on AWS.
The Cloud Formation template may be used as is or further customized to meet specific project needs (such as adding additional AWS resources, such as RDS, or changing the region or availability zones in which the cluster is run). We can also easily customize which add-ons will run on the cluster.
From a security perspective, the new cluster is secure by default, thanks to the following features:
- The Kubernetes cluster etcd is configured with transport layer security (TLS) for clients and cluster nodes access.
- The cluster API server is configured with TLS for client access.
- Default Kubernetes access control is configured with a single administrator user account and different service accounts for each Kubernetes service.
- All account tokens and passwords are randomly generated.
- All TLS keys, certificates, and Kubernetes secret tokens and passwords are generated on the first start of the master server, and distributed via a unique S3 bucket.
- Key, certificate, and token files used to configure Kubernetes components on master and node instances are placed to tmpfs mounted directories, so secret information is never saved on disks (except for the S3 bucket).
- The secret files placed to the S3 bucket are configured with ACL only enabling access to the cluster master and node instance roles (and the AWS account administrator).
The new cluster is also reliable:
- In case of a node failure, a new node will be started by the node’s Auto Scaling Group, and the new node will automatically join the cluster to recover available compute capacity.
- In case of a master failure, a new master instance will be started by the master Auto Scaling Group. The new master instance will automatically re-attach the master EIP, the master EBS, and therefore restore the cluster functionality and configuration as it was before.
- Further reliability improvement may be achieved via configuring regular EBS backups via snapshots. This process may itself be run as a pod or an add-on within the Kubernetes cluster.
- The nodes auto-scaling group is configured by default to span multiple availability zones.
The cluster is also scalable:
- The lowest scale possible is a single master node, which may run user load due to the fact that the master kubelet is configured to register with the master API server.
- Scaling is possible via adding more nodes in the nodes auto-scaling group.
We also made sure that we are not limiting our options:
- The deployment procedure can be easily extended to other linux distributions, platforms, and cloud providers due to the fact that all kubernetes components are started in docker containers.
Next Steps and Future Work
Having achieved the minimal set of features required to run a Kubernetes cluster in production, there is still space for improvement:
Currently, the cluster is vulnerable to a failure of the availability zone where the master node is running. The master auto-scaling group is intentionally limited to a single availability zone due to AWS EBS limitations (EBS cannot be used in an availability zone different from the one in which it was initially created). There are two ways of overcoming this issue:
- By regular snapshotting the master EBS and automatic recovery from the latest snapshot in a different availability zone. This is suitable for extra-small deployments where only self-healing is required and some downtime is acceptable.
- By setting up multi-master Kubernetes configuration. A default configuration for large scale deployments (most of the deployments, in fact).
We are planning to implement both.
Even with the improvements described above, the cluster will still be vulnerable to whole region failures. Because of this, we are planning to introduce cluster federation as an option, and entertain different automated disaster recovery strategies for inter-region and hybrid deployments.
Security may also be improved with EBS encryption, embedding tools such as HashiCorp Vault, and potentially changing secrets distribution strategy.